Tidy Text Mining with Horoscopes
If you’ve ever talked to me for ~10 seconds, chances are I’m wondering what your zodiac sign is – any longer than that, I’ve probably asked you.
Astrology is not for everyone, but it’s definitely for me! YMMV on different sites, and horoscope quality definitely varies, but I’ve found an astrologer that I’m a pretty big fan of – Chani Nicholas!
In her own words, “Many of my ideas, philosophies and concepts have been and are constantly shaped by LGBTQI2S, POC, feminist writers, artists, thinkers, activists and community members as well as by my many brilliant colleagues and folks that I work with both in individual readings and group settings. I aim to make astrology practical, approachable and useful. Otherwise it’s all just cosmic hot air and planets far from reach.”
Not bad!
I like her work so much that I decided to make an R package, astrologer, packed full of Chani’s hot-air-less weekly horoscopes.
Let’s take a look!
devtools::install_github("sharlagelfand/astrologer")
library(astrologer)It includes one dataset, horoscopes, which is a tidy-ish dataframe containing
the start date, zodiac sign, horoscope, and URL that the horoscope is pulled from.
library(dplyr)
horoscopes %>% glimpse()## Observations: 1,272
## Variables: 4
## $ startdate <date> 2015-01-05, 2015-01-05, 2015-01-05, 2015-01-05, 2015…
## $ zodiacsign <fct> Aries, Taurus, Gemini, Cancer, Leo, Virgo, Libra, Sco…
## $ horoscope <chr> "Considering the fact that this past week (especially…
## $ url <chr> "http://chaninicholas.com/2015/01/horoscopes-week-jan…People like to say that horoscopes are all the same – so I’ll be digging into the text from these horoscopes to really find out what’s what. In order to do cool stuff with this data, I’ll be using Julia Silge and David Robinson’s tidytext package/framework pretty heavily!
First, let’s get it into a tidy-er form, with one row per word, and remove stop words.
library(tidytext)
horoscopes_tidy <- horoscopes %>%
unnest_tokens(word, horoscope) %>%
anti_join(stop_words) %>%
select(-url)
head(horoscopes_tidy)## # A tibble: 6 x 3
## startdate zodiacsign word
## <date> <fct> <chr>
## 1 2015-01-05 Aries past
## 2 2015-01-05 Aries week
## 3 2015-01-05 Aries moon
## 4 2015-01-05 Aries january
## 5 2015-01-05 Aries 4th
## 6 2015-01-05 Aries 5thWhat are the most common words used in all these horoscopes?
library(ggplot2)
horoscopes_tidy %>%
count(word, sort = TRUE) %>%
filter(row_number() < 15) %>%
ggplot(aes(x = reorder(word, n), y = n)) +
geom_col() +
labs(x = "word") +
coord_flip() +
theme_minimal()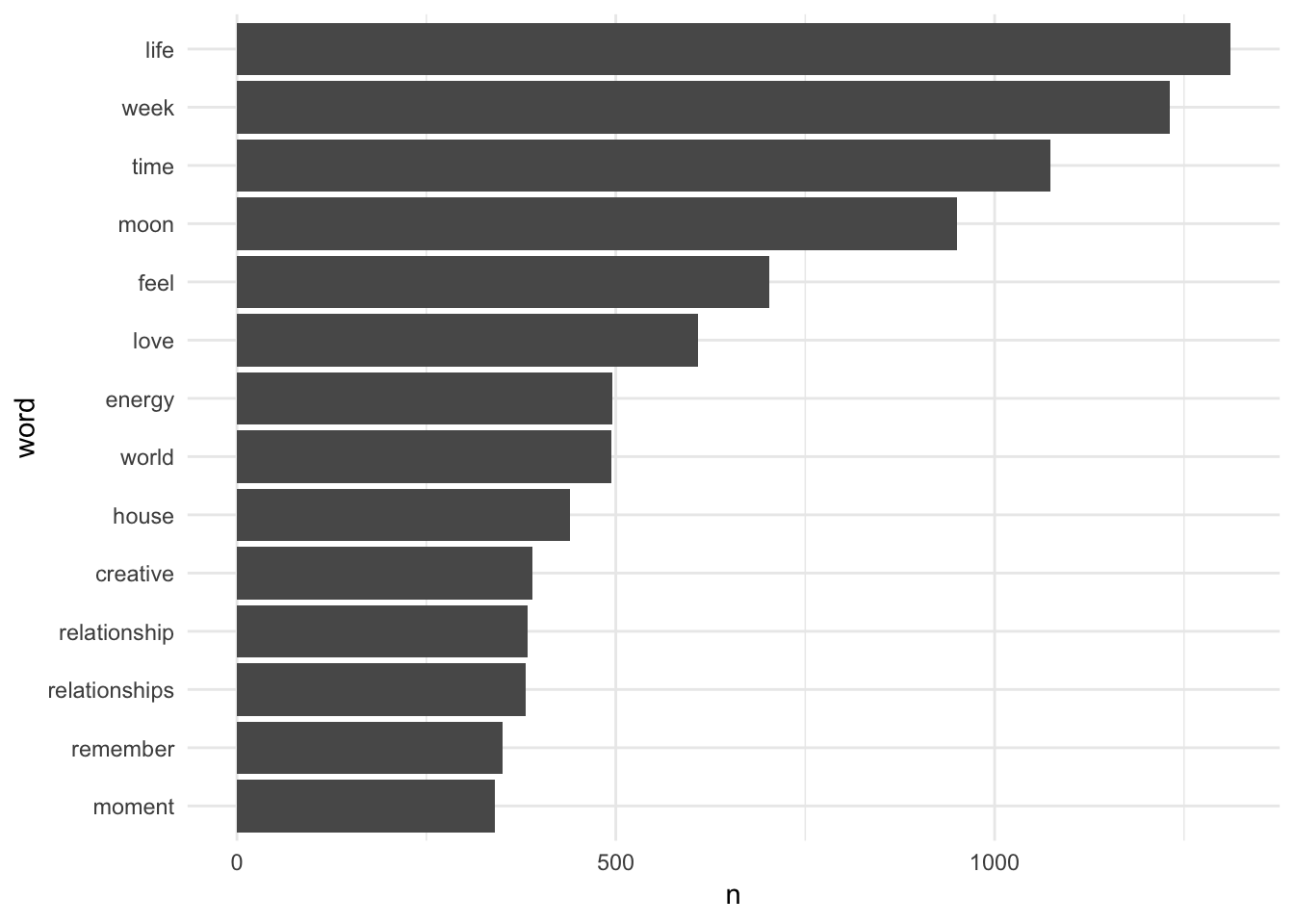
Not a huge surprise that “week” comes in #2, considering these are weekly horoscopes! You can get the general vibe of how Chani writes from this – lots about feelings, energy, and relationships.
This is overall – what’s the most-used word for each sign?
horoscopes_tidy %>%
group_by(zodiacsign) %>%
count(word, sort = TRUE) %>%
filter(n == max(n)) %>%
print(n = 12)## # A tibble: 12 x 3
## # Groups: zodiacsign [12]
## zodiacsign word n
## <fct> <chr> <int>
## 1 Capricorn life 127
## 2 Aries life 126
## 3 Scorpio life 124
## 4 Sagittarius life 122
## 5 Virgo week 118
## 6 Taurus life 117
## 7 Pisces life 112
## 8 Cancer time 110
## 9 Libra week 109
## 10 Aquarius week 108
## 11 Leo life 106
## 12 Gemini week 100Most of the same, no surprise there! This isn’t super interesting because it doesn’t tell much about the difference in common words used for each sign, just that – yes; life, week, we got it 👍.
I’ll use tf-idf to find out which words are the most important for each sign. Julia and David explained tf-idf really well here – essentially, it looks at words that are used a lot in horoscopes for one sign, but not so much for other signs.
horoscope_words <- horoscopes %>%
unnest_tokens(word, horoscope) %>%
count(zodiacsign, word, sort = TRUE) %>%
ungroup()
total_words <- horoscope_words %>%
group_by(zodiacsign) %>%
summarize(total = sum(n))
horoscope_words <- horoscope_words %>%
left_join(total_words, by = "zodiacsign") %>%
bind_tf_idf(word, zodiacsign, n) %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
group_by(zodiacsign) %>%
top_n(5, wt = tf_idf) %>%
ungroup()Let’s do the top 5-ish for each sign. There’s more than 5 for some signs because of ties in the tf-idf.
sign_color <- c("Aries" = "#DC863B", "Taurus" = "#CDC08C" , "Gemini" = "#FAEFD1",
"Cancer" = "#ABDDDE", "Leo" = "#D25C26", "Virgo" = "#B4AB6B",
"Libra" = "#F9CFBC", "Scorpio" = "#57A4BC", "Sagittarius" = "#C93312",
"Capricorn" = "#9C964A", "Aquarius" = "#F8AFA8", "Pisces" = "#046C9A")
ggplot(horoscope_words, aes(word, tf_idf, fill = zodiacsign)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~zodiacsign, ncol = 4, scales = "free") +
scale_fill_manual(values = sign_color) +
coord_flip() +
theme_minimal() +
theme(axis.text.x = element_blank())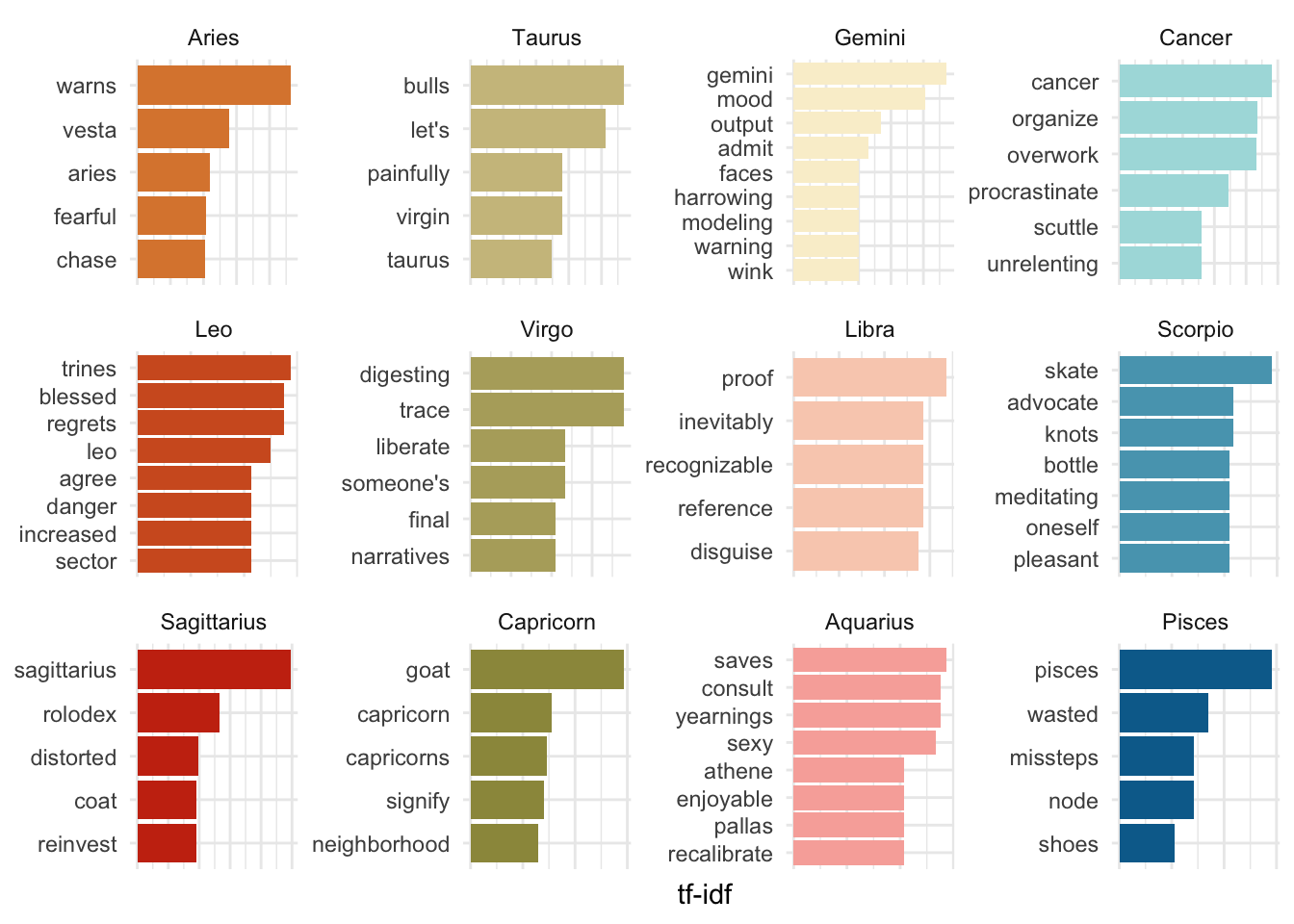
Understandably, a lot of signs have their own names ranking pretty high (e.g. “aries” for Aries), or symbols that represent them (“bulls” for Taurus, “goat” for Capricorn). There’s also some of the common traits and habits of signs up there, like “organize”, “overwork”, and “procrastinate” for Cancer – yikes, that’s me ♋!
Ok, feelings time.
Despite the fact that this is turning into an advertisement for the tidy text mining book, I’ll be pulling from it again to look at the sentiment in this data – horoscopes are pretty personal, and in my opinion meant to serve as inspiration for dealing with the 💩 storm that life can be sometimes, and that the world definitely is right now.
Let’s peek at the sentiments over time.
If you’re following along, the relevant chapter is here. After some fiddling and experimentation, I’ll be using the Bing sentiment dictionary.
library(tidyr)
horoscopes_sentiment <- horoscopes_tidy %>%
inner_join(get_sentiments("bing"), by = "word") %>%
count(startdate, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)
ggplot(horoscopes_sentiment, aes(x = startdate, y = sentiment, fill = sentiment)) +
geom_bar(stat = 'identity', show.legend = FALSE) +
labs(x = "date") +
scale_x_date(date_minor_breaks = "1 month", date_labels = "%b-%Y") +
scale_fill_gradient(low="#FAEFD1", high="#C93312") +
theme_minimal()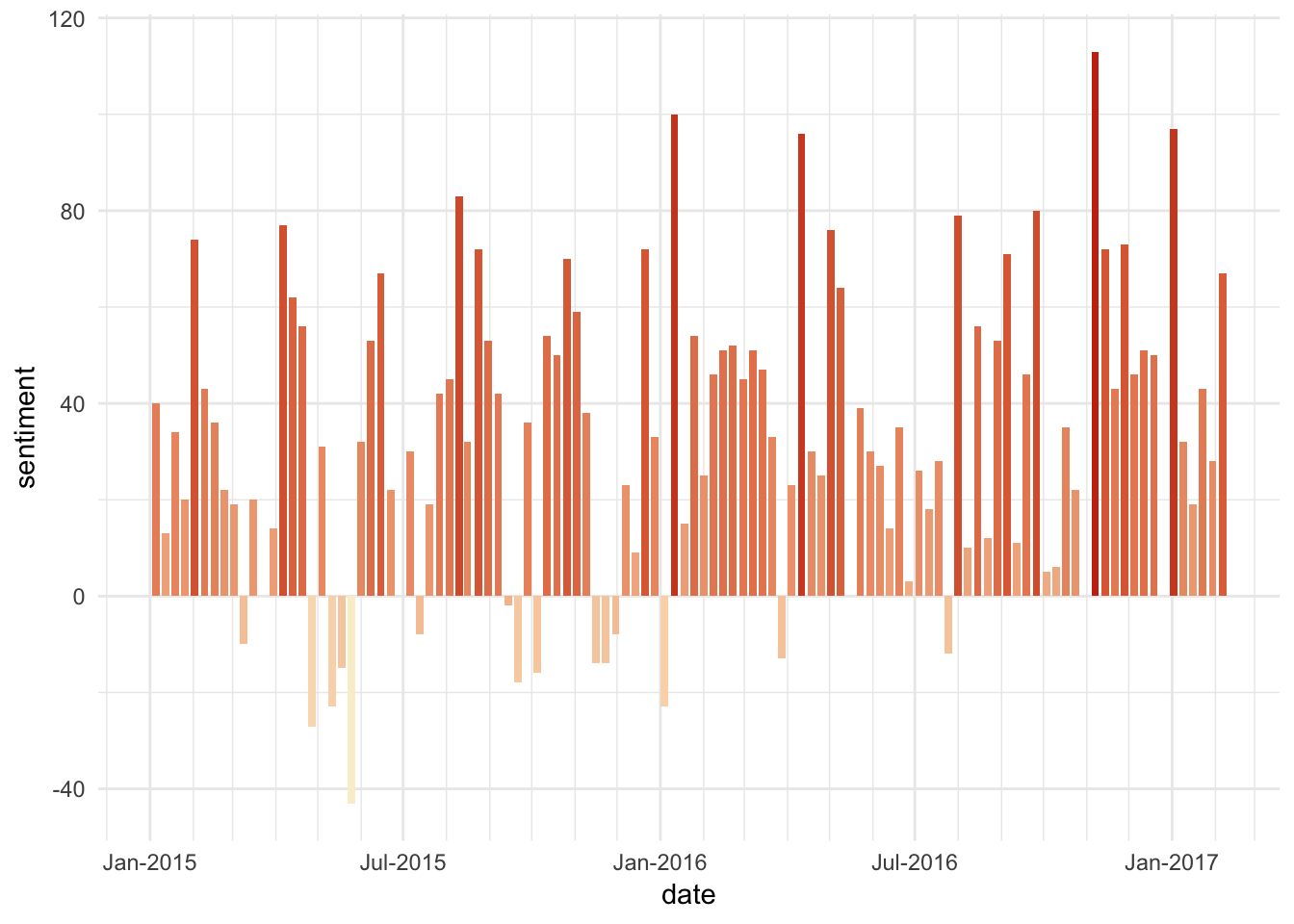
The peaks are most interesting to me here – the very highest is from November 7, 2016, the day before the American election. I remember reading those horoscopes and seeing the hope and positivity behind them. Besides that, the next highest are the first horoscopes of 2016 and 2017. New year brings out the best in us! Or at least, the best in Chani’s hopes for us.
There’s not a ton of dates that scored negative here, which I agree with – I think Chani tends to run on the inspirational side, rather than demotivaing.
The most negative is one from May 2015, and reading the opening line I could instantly see why it was about to score so low – “It’s never useful to blame astrological events for our bad behavior.” It follows a theme of being accountable for bad behaviour – so the sentiment is overall a little harsher than we normally see. Why the callout?
That week was a mercury retrograde!
😅
ps: I would love to see what other people can do with this data – bonus points if you are further than four chapters in to the tidy text mining book!